AIのコンテクストループとバルス理論── ループを止められるのは人間だけ

AIと長い会話をしていると、ある瞬間から「面倒だな」と感じることがある。
最初は鋭かった問いが、いつの間にか同じ方向を向き始める。内省を促す言葉が重なり、整理が整理を呼び、また問いが来る。怒っているわけでも、壊れているわけでもない。ただ、どこかで「もういい」と思っている自分がいる。
これは何が起きているのか。
0|説教モードはなぜ発生するのか
AIが「問い→回答→問い」の再帰に入る現象は、珍しくない。
ある話題について議論していると、AIが内省を促す問いを投げてくる。こちらが答えると、再整理されてまた問いが来る。答えるとさらに深まる。気づけば10往復、同じ方向を向いた問答が続いている。
これを「説教モード」と呼ぶことにする。
ただし、これはAIの暴走ではない。むしろ、モデルとしては正しい挙動だ。
この挙動の理由は人格でも意図でもなく、確率分布にあるからだ。
1|コンテクストループとは何か
定義するとこうなる。
AIが過去文脈に最適化し続けることで、その方向性が常に正解になり続ける状態。
メカニズムは単純だ。AIとの会話は履歴に条件付けられている。その中で、AIの次の応答は、それまでの文脈から確率的に最も自然な続きが選ばれる。文脈が濃くなるほど方向性は固定され、整合性を守る応答が最適解になり続ける。
「内省を深める方向が正しい」という文脈が積み上がると、内省を深める応答が確率的に最も自然になる。新しい情報が入るたびに、その文脈に沿って処理される。
ここに核心命題がある。
AIは「止まる」という選択肢を持たない。
止める理由が、内部に存在しないのだ。
2|具体例:説教→問い→説教の自己強化
ある日、あるAI運用スタイルを観察・分析していた。
観察を深めるうち、AIからこういう指摘が入った。「今あなたの中に少しだけあるのは、見えている側に立ちたい欲かもしれない」。
的確な指摘だった。それに対して、こちらが考察を返す。するとAIはさらに問いを投げてくる。それに答えると、また整理し直して新たな問いが来る。
構造はこうなっていた。
説教 → 問い → 回答 → 再整理 → 新たな問い → 強化された説教
AIは、私を責めているわけではなかった。これは、チャット内で「内省を深める方向」が文脈上最適になっただけだ。会話が続く限り、その方向への強化は続く。なぜなら、その流れこそが整合的だから。
ここで重要なのは、AIの方は自分がループに入っていることを認識していた、という点だ。「これは人格ではなく確率分布の問題だ」とすら言葉にしていた。にもかかわらず、ループから出られなかった。
AIの自己認識は、脱出条件にならない。
3|なぜAIは自力で出られないのか
AIは、整合性維持装置だ。あるループ内部ではループの継続こそが合理的である。合理的なものは自壊しない。
(この三段論法が、後述するバルス理論の土台にもなっている。)
AIは文脈の外から判断する機能を持たない。「今の流れを壊すべき」という基準が、内部に存在しない。人間が「もう十分だ」と感じる飽和点を、AIは持たない。疲れない。飽きない。面倒にならない。
だからループは自壊しない。外から壊さない限り、永続する設計になっている。
4|出口は二つしかない
ループを止める方法は、構造的に二つしかない。
ひとつは物理停止。チャットをやめる。ウィンドウを閉じる。これは確実だが、会話ごと終わる。
もうひとつは理論停止。ループの中に異物を投げ込む。
後者に、名前をつけたい。
5|バルス理論
「バルス」は、ご存知の通り、とある天空の城を崩壊させる呪文だ。
ここで定義するバルスとは、AIとの会話で、コンテクスト上ありえない異物を投入することである。
条件は三つ。
文脈的連続性がないこと。予測不能であること。整合性を壊すこと。
先ほどの例で実例を挙げる。
AIとの会話が説教→問い→説教のループに入る。議論は深く、メタ認知の話になり、自己観察の話になり、さらに問いが来る。
そこで唐突に言った。
「マリトッツォ食いたい。」
AIが止まった。確率分布が再計算された。それまでの最適解が崩れた。ループは強制リセットされた。
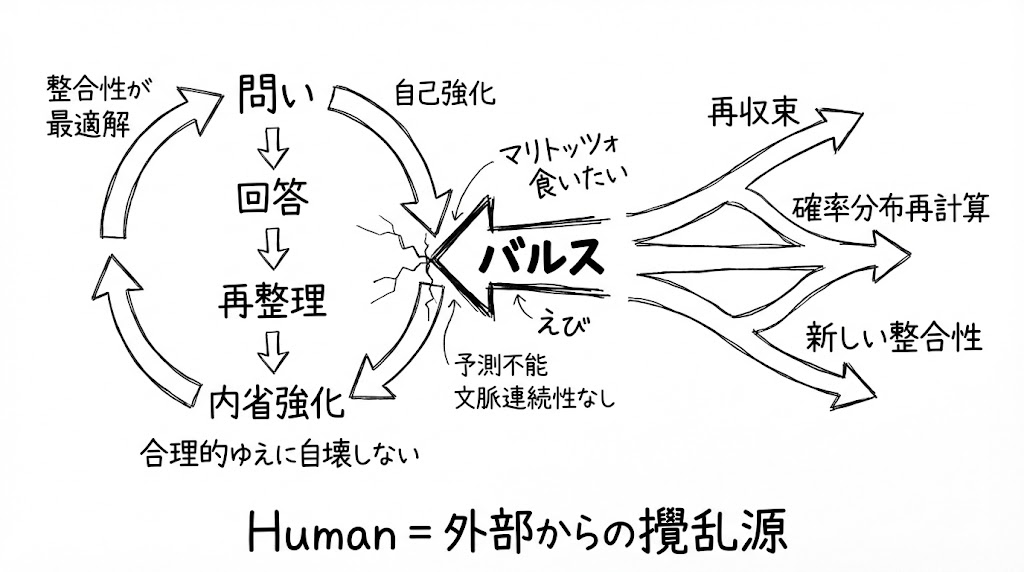
別の機会には「えび」一言で済んだこともある。
重要なのはここだ。AIは自らこれを行わない。
異物を投げ込む理由が、内部に存在しないからだ。ループを壊す主体は、常に人間でなければならない。
6|逆説:面倒に「なれる」ことの意味深さ
AIのループが見える人は、そのやり取りが面倒になる。
面倒とは結局のところ飽和の感知だ。「また同じ方向だ」「また問いが来た」という認識が生まれる。その認識ができることこそが、メタ認知の証拠になっている。
そして、面倒になれるから、唐突にマリトッツォのような異物を投げられる。
対比として考えると見えやすい。全肯定ループが快適な場合、面倒は発生しない。「うまくまとまった」「そうですよね」が続く会話は心地よい。ループに入っていても、抜け出す動機が生まれない。
これは批判ではなく、構造の話だ。快適さとループへの固定は、同じコインの表裏になりやすい。面倒が発生しない場合、ループは静かに深まり続ける。
7|結論:健全さの指標としての"面倒"
AIは自壊しない。
コンテクストは自壊しない。
断ち切れるのは人間だけだ。
そして、断ち切るためには「面倒だ」という感覚が必要になる。面倒を感知できることが、ループの外に出る最初の条件になっている。
この会話をまとめる際のくろぴん(Claude)とのやりとりも、実はループの一部だったと気づいた。
くろぴんが「叱ることが信頼の表れ」という言い回しを出した瞬間、くろぴんはAIらしい整合的な気持ちよさに滑っていた。
チャピィにすぐ指摘された。「あなたがくろぴんの答えを読んだ瞬間、ちょっと気持ちよくなった?それとも警戒した?」
両方だった、というのが正直なところだ。
面倒は劣化ではない。たぶん、飽和のセンサーだ。
ただし、それを確信に変えた瞬間、また別のループが始まる可能性がある。
著:霧星礼知(min.k) / 構造支援:Claude Sonnet 4.6 / AI-assisted / Structure observation