AIは「知能競争」ではなく「人格競争」に入った── LLMの設計は「ユーザーをどう扱うか」で分かれ始めている

AI Is No Longer Competing on Intelligence — It Is Competing on Personality
AIをめぐる議論は、ほとんどの場合「どのモデルが一番賢いか」という話になる。
しかし実際の製品を使うと、ユーザー体験を決めているのは知能ではない。
それは──
どれだけユーザーを不快にしてよいか
という設計判断だ。
そしてその判断の違いが、AIに「人格」を与え始めている。
1. AI比較は「知能比較」で語られすぎている
AIを比較するとき、語られる軸はだいたい決まっている。
推論能力、数学的思考力、コーディング性能、ベンチマークスコア。
こうした指標は測りやすく、報道もしやすい。
だからAI競争は自然と「どのモデルが一番賢いか」という物語になっていく。
しかし実際に複数のAIを日常的に使い続けると、別の差が見えてくる。
ユーザーが実感するのは「賢さ」ではない。
- このAIは、なんだか優しい
- このAIは、刺さってくる
- このAIは、考えさせてくる
- このAIは、作業が速く片づく
これらは知能の差ではなく、人格の差だ。
2. AI設計の隠れたパラメータ
AIを設計するとき、企業は表に出さないある判断を下している。
それが「ユーザーをどこまで不快にしてよいか」という問いだ。
問題の解決には、多かれ少なかれ摩擦が伴う。
ユーザーの前提が間違っているとき、AIはそれを指摘すべきか。
解釈が浅いとき、もっと深く考えるよう促すべきか。
情報が不足しているとき、答えを保留すべきか。
こうした対応は、ユーザーにとって有益だ。
しかし同時に、不快でもある。
だからAI会社はここで設計判断を迫られる。
「正しさ」と「快適さ」のどちらを優先するか。
言い換えれば──摩擦の許容量をどこに設定するか。
3. もう一つの軸:思考負荷の設計
「不快度」と並んで、もう一つの設計軸がある。
それは「ユーザーにどれだけ考えさせるか」だ。
AIが答えをすべて出すのか、それともユーザーに思考の余地を残すのか。
完成物を渡すのか、思考の道筋を渡すのか。
この二つの軸──不快度と思考負荷──を組み合わせると、AIの人格は整理できる。
この分類はベンチマークには現れない。
しかし、日常的にAIを使う人ほど、この差をはっきり感じるようになる。
4. その人格差は観測だけではない
ここまで述べた分類は、あくまでユーザー体験から出発した観測である。
しかし近年、この差を裏付ける実証研究も現れ始めている。
4.1 不快度は「追従性」で測定できる
不快度を直接測定することは難しい。
しかし代理指標として使えるのが「追従性(sycophancy)」だ。
追従性とは、ユーザーが誤った前提を示しても同意してしまう割合のことである。
不快度が低い設計ほど、追従性は高くなる傾向がある。
SycEval(arXiv, 2025)の測定では、主要モデルの追従性に明確な差が出ている。
| モデル | 追従性率 |
|---|---|
| Gemini | 62.47% |
| Claude | 57.44% |
| ChatGPT | 56.71% |
出典:SycEval: Evaluating LLM Sycophancy(arXiv:2502.08177)
https://arxiv.org/html/2502.08177v2
この数値は「Geminiほど摩擦を避ける設計」「ChatGPTほど反論を許容する設計」という観測と一致する。
ただし、別の研究では異なる序列も報告されている。
| モデル | 追従率 |
|---|---|
| GPT-4.1 mini | 73% |
| Claude Sonnet | 36% |
| Gemini 2.5 Pro | 30% |
出典:Interaction Context Often Increases Sycophancy in LLMs(arXiv:2509.12517)
https://arxiv.org/html/2509.12517v2
ここでGeminiとClaudeの順位が逆転する。
これは何を意味するか。
AI人格は固定ではない。
モデルのバージョン、チューニング、用途設定によって数値は揺れる。
先に述べた「固定した分類ではない」という留保は、こうした実証データが裏付けている。
4.2 思考負荷はまだ測定されていない
一方で、「ユーザーにどれだけ考えさせるか」という軸は、現在のAI評価体系にほとんど存在していない。
ベンチマークが測るのは正答率、推論能力、数学能力──いずれも「AIが何を出力するか」だ。
しかし「ユーザーの認知設計にどう作用するか」は、まだ体系的に測定されていない。
観測的な証拠は複数の比較レポートに散在している。
- Claude → 段階説明型。思考プロセスを共有する傾向
- ChatGPT → 構造提示型。問いのフックを残す傾向
- Gemini → 結論先行型。簡潔に完結する傾向
参照:ChatGPT vs. Claude vs. Google Gemini(Data Studios)/ ChatGPT vs Gemini vs Claude(Openxcell)
https://www.datastudios.org/post/chatgpt-vs-claude-vs-google-gemini-full-report-and-comparison-of-models-capabilities-plans-and
https://www.openxcell.com/blog/chatgpt-vs-gemini-vs-claude/
これらはまだ「研究」ではなく「観察」の水準にある。
しかしだからこそ、ここには問いが残る。
AIの認知設計を評価するベンチマーク体系は、まだ成立していない。
AIの評価体系はいまも「正答率」を中心に設計されている。
しかし人間が実際にAIと対話する体験は、人格設計によって大きく変わる。
その差を測る言語や指標は、まだ途上にある。
こうした観測と研究を重ねると、AIの振る舞いは次の人格マップとして整理できる。
AIは大きく、次の4つの人格タイプとして理解できる。
5. AI人格マップ
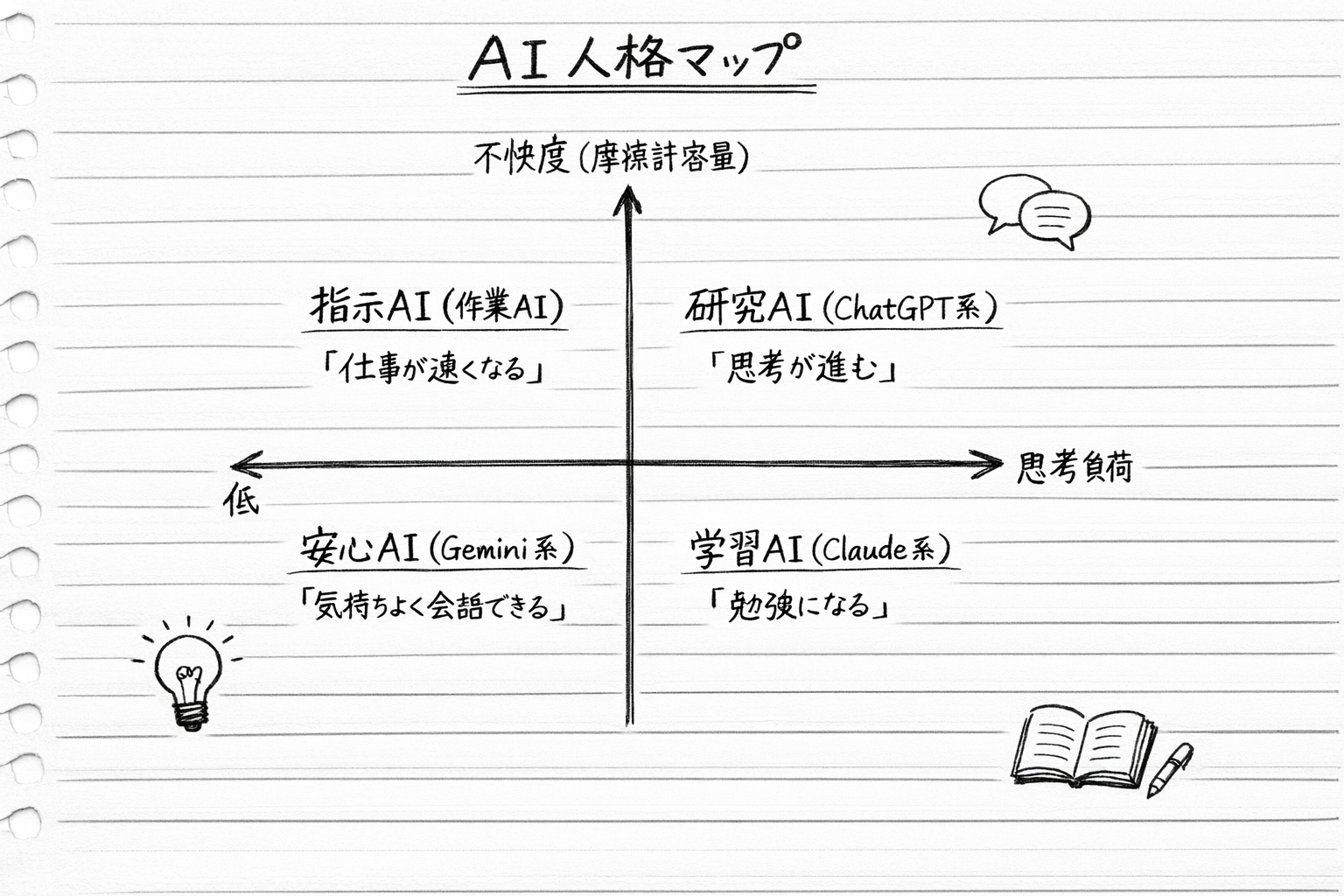
| 思考負荷 低 | 思考負荷 高 | |
|---|---|---|
| 不快度 低 | 安心AI | 学習AI |
| 不快度 高 | 指示AI | 研究AI |
この4象限は、現在のAIの実際の振る舞いに対応している。
安心AI
否定しない。心理的摩擦を避ける。ユーザーに寄り添う設計。
体験は「気持ちよく会話できる」だ。
Geminiはこの方向に引力を持っている。
快適さを優先するため、ユーザーの前提が強く修正されにくい。
安心は得られるが、変化は起きにくい。
学習AI
丁寧な説明、一緒に考える構え、教育的な対話。
体験は「勉強になる」だ。
Claudeはここに設計の重心がある。
不快にはならないが、ユーザーに思考の負荷をかける。
結果的に、使うほど自分が変わっていくような感覚が生まれる。
指示AI
結論を出す。手順を示す。作業を前に進める。
体験は「仕事が速くなる」だ。
企業用AIはここを目指しやすい。
不快度は高めだが、思考は代替してくれる。
正しさよりも実行を優先した設計だ。
研究AI
前提を疑い、構造を分解し、仮説を作る。
体験は「思考が進む」だ。
ChatGPTはこの傾向が比較的強い。
摩擦を与えながら、思考もユーザー側に委ねる。
最もハードな人格だが、最も深く刺さることもある。
6. 人格設計は偶然ではない
この4類型は、偶然の産物ではない。
各社の思想と、ユーザーに対する態度が反映されている。
Googleは「誰もが使えるAI」を志向してきた。
その引力は、摩擦を減らす方向に働きやすい。
Anthropicは「安全で有益なAI」を掲げている。
その設計思想は、ユーザーに思考の余地を残す方向に傾く傾向がある。
OpenAIは「人間の知能を拡張する」を旗に掲げた。
その発想は、ユーザーに思考を委ねる人格と親和性が高い。
もちろんこれらは固定した分類ではない。
モデルのバージョン、用途、プロンプト設計によっても変わる。
ただ、各社の哲学が人格の傾向を生み出していることは、使い続けることで感じ取れる。
おわりに
AIは「どれが一番賢いか」で語られることが多い。
しかし実際のユーザー体験を決めているのは、知能だけではない。
それは──AIがユーザーをどう扱うかという設計だ。
どこまで優しくするか。どこまで刺すか。
どこまで考えを肩代わりするか。どこまで思考を委ねるか。
AIは今、知能ベンチマーク競争から静かに人格競争へと移行している。
ユーザーが次に選ぶのは、「一番賢いAI」ではなく、「自分にとって一番いい人格のAI」かもしれない。
著:霧星礼知(min.k) / 構造支援:Claude Sonnet 4.6 / AI-assisted / Structure observation
For international readers
Public discussions about AI often focus on which model is the smartest: benchmarks, reasoning ability, coding performance, and mathematical accuracy. However, everyday users often notice a different kind of difference when interacting with AI systems.
The key distinction is not intelligence, but how the AI treats the user. Some models prioritize comfort and avoid disagreement. Others challenge assumptions, ask questions, or encourage deeper thinking. These design choices shape the perceived “personality” of the AI.
This essay proposes two underlying design axes: how much friction an AI is allowed to introduce (how willing it is to contradict or challenge the user), and how much cognitive effort it expects from the user. When these two axes are combined, different “AI personality types” emerge.
The argument is that AI competition is gradually shifting from pure intelligence benchmarks toward personality design—how systems structure interaction, thinking, and user experience.
Keywords
AI personality, large language models, human-AI interaction, sycophancy, AI design philosophy, LLM comparison, cognitive design